Morphik 파싱 없이 이미지만으로 RAG를 실현
Morphik은 복잡한 문서를 정확히 검색할 수 있도록 설계된 RAG(Retrieval-Augmented Generation) 도구를 개발하고 있다. 많은 시스템이 OCR 및 파싱에 의존하는 반면, Morphik은 '페이지 이미지' 자체를 정보의 원천으로 활용하는 방식을 선택하였다. 이 글에서는 왜 시각적 접근이 기존 방식보다 우수한지, 그리고 이를 통해 어떻게 정확도와 속도를 모두 확보할 수 있었는지를 설명한다.
파싱의 한계: 왜 텍스트만으로는 부족한가
복잡한 PDF 문서를 다뤄본 사람이라면 누구나 겪는 문제다. 표와 차트, 도표, 설명 텍스트가 혼재된 문서는 일반적인 OCR 기반 파이프라인으로 처리하기 어렵다. 예를 들어 회계 보고서의 도넛 차트나 기술 매뉴얼의 주석 달린 다이어그램은 텍스트보다 더 중요한 정보를 담고 있지만, 파이프라인은 이를 놓치기 쉽다.
기존의 문서 처리 파이프라인은 다음과 같은 단계를 거친다.
-
OCR을 통해 문자 인식
-
레이아웃 분석을 통한 테이블 및 구성요소 분리
-
텍스트의 시각적 순서를 복원
-
그림 및 차트에 캡션 생성
-
텍스트 청킹
-
임베딩 모델로 의미 벡터 생성
-
벡터 DB에 저장 후 검색
이 중 하나라도 실패하면 전체 검색 정확도가 떨어진다. 특히 위치 정보 손실, 텍스트-이미지 임베딩 간의 의미 단절, 복잡한 테이블 구조의 해석 오류 등은 치명적인 영향을 준다.
전환점: “그냥 페이지를 보면 안 될까?”
Morphik의 공동 창업자는 다음과 같은 질문을 던졌다. “왜 문서를 분해하고 다시 의미를 조합하려 드는가? 사람처럼 그냥 ‘문서 전체를 시각적으로’ 보면 되지 않을까?”
이 질문은 Morphik의 방향을 바꾸는 결정적 계기가 되었다. 최신 Vision-Language Model은 더 이상 OCR이나 파싱 없이도 문서 이미지를 직접 이해할 수 있을 만큼 발전하였다.
ColPali: 문서를 시각적으로 이해하는 방식
Morphik이 구현한 핵심 모델은 ColPali 기반이다. 이 접근법은 다음과 같이 동작한다.
-
각 페이지를 고해상도 이미지로 처리
-
이미지를 패치 단위로 분할
-
각 패치를 Vision Transformer(SigLIP-So400m)로 인코딩
-
문서 구조를 이해하도록 훈련된 PaliGemma-3B로 임베딩을 정제
-
질의에 대해 ‘지연 상호작용(late interaction)’ 방식으로 연관 패치 검색
이 모델은 단순히 “Q3 revenue”라는 키워드를 찾는 것이 아니라, 관련된 표, 차트, 색상 정보까지 종합적으로 분석하여 응답한다.
기존 방식과의 비교: 수치로 입증된 차이
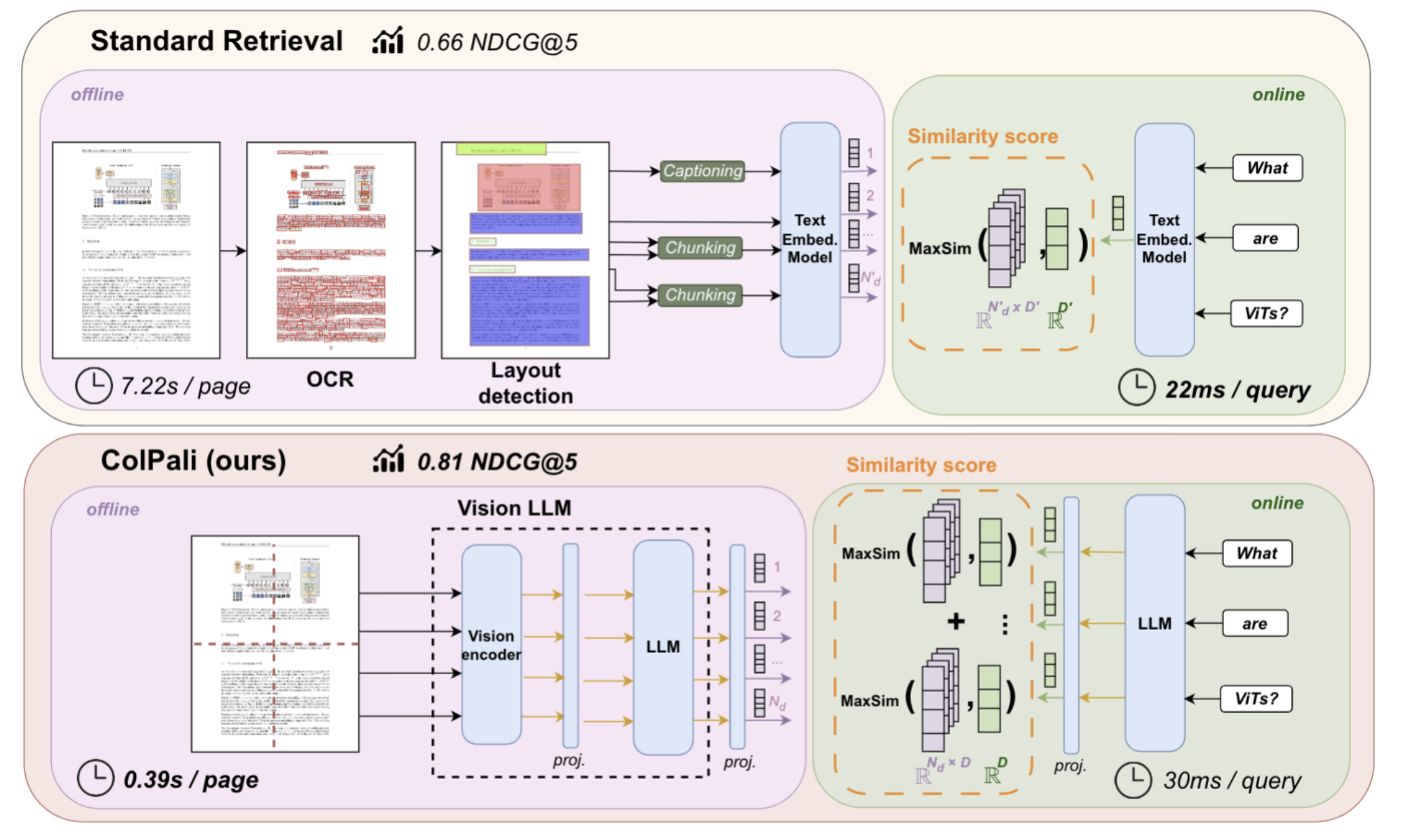
Morphik은 TLDC(The LLM Data Company)와 협업하여 NVIDIA 10-Q, Palantir 발표자료, JPMorgan 보고서 등 복잡한 재무 문서를 포함한 벤치마크를 만들었다. 총 45개의 고난도 질문으로 구성된 이 벤치마크에서 Morphik은 95.56%의 정확도를 기록하였다. 반면, LangChain 기반 RAG 시스템은 72%, OpenAI File Search는 13.33%에 그쳤다.
ViDoRe 벤치마크에서는 nDCG@5 기준 Morphik이 81.3%를 기록하여 전통적 방식(67.0%)을 크게 상회하였다.
속도 문제와 MUVERA를 통한 해결
시각적 RAG 시스템은 정확하나 처음엔 느렸다. 수백만 개의 이미지 패치를 실시간 검색하는 것은 현실적으로 3~4초의 지연을 야기하였다. 이 문제를 해결한 것이 MUVERA 알고리즘이다. MUVERA는 멀티 벡터를 단일 벡터로 압축하여 빠른 검색을 가능하게 하였다. Morphik은 이를 적용한 자체 벡터 DB인 Turbopuffer와 결합하여 검색 속도를 30ms로 줄였다.
활용 사례와 API
Morphik의 시각 기반 문서 검색은 다음과 같은 문서에 특히 강력하다.
-
재무 문서: 표와 차트가 핵심 정보를 담고 있는 경우
-
기술 매뉴얼: 도표가 주요 설명 수단인 경우
-
영수증/인보이스: 레이아웃이 의미를 갖는 경우
-
연구 논문: 핵심 결과가 그림에 담긴 경우
-
의료 기록: 시각적 구성이 진단 정보를 내포하는 경우
API 사용 방식은 단순하다. 문서를 업로드하고 자연어로 질의하면 된다. 예: “총액이 $10K를 초과하는 벌칙 조항이 포함된 계약서 찾아줘” 또는 “작년 제안서에 포함된 시스템 아키텍처 다이어그램 보여줘”.
미래: 문서의 맥락과 논리를 이해하는 시스템으로
Morphik은 단순 검색을 넘어, 다음과 같은 고차원적 문서 이해를 지향한다.
-
다문서 추론: 문서 간의 논리적 연결 파악
-
에이전트 기반 추론: 문서 간 조건 비교, 규정 일치 확인, 실행 계획 연결 등
-
워크플로우 통합: 계약서 불일치 자동 탐지, 설계-구현 간 이력 추적 등
한계와 과제
Morphik은 시각 기반 검색으로 기존 파싱 방식이 놓치던 정보를 효과적으로 찾을 수 있게 하였으나, 인간 전문가 수준의 해석 능력까지는 아직 도달하지 못하였다. 금융 분석가가 수치 이면의 맥락을 이해하듯이, 향후 과제는 도메인 지식과의 통합, 인과 추론, 신뢰도 계산 등으로 확장되는 것이다.